A Game-based Framework for Cooperative Driving at Mixed Un-signalized Intersections
Yiming Cui, Shiyu Fang, Qian Chen, Peng Hang, Jian Sun
Abstract
During the ongoing development and proliferation of autonomous vehicles, human-driven vehicles (HDVs) and connected and automated vehicles (CAVs) will coexist in mixed traffic environments for the foreseeable future. However, current autonomous driving systems often face challenges in ensuring optimal safety and efficiency, particularly in complex conflict scenarios. To address these shortcomings and improve cooperation in mixed traffic environments, this paper presents a cooperative decision-making method based on game theory. The proposed framework accounts for both CAV-CAV collaboration and CAV-HDV interaction in mixed traffic at un-signalized intersections. this study introduces a parameter updating mechanism based on twin games to dynamically adjust HDVs’ parameters to better predict and respond to variable human driving behaviors. To validate the effectiveness of the proposed cooperative driving framework, we compared its safety and efficiency with other established methods. The results demonstrate that our nethod successfully ensures both safety and efficiency in mixed traffic environments. Additionally, several validation experiments were conducted using a hardware-in-the-loop and human-in-the-loop experimental platform built on CARLA, confirming the practical applicability of the method.
Method Overview
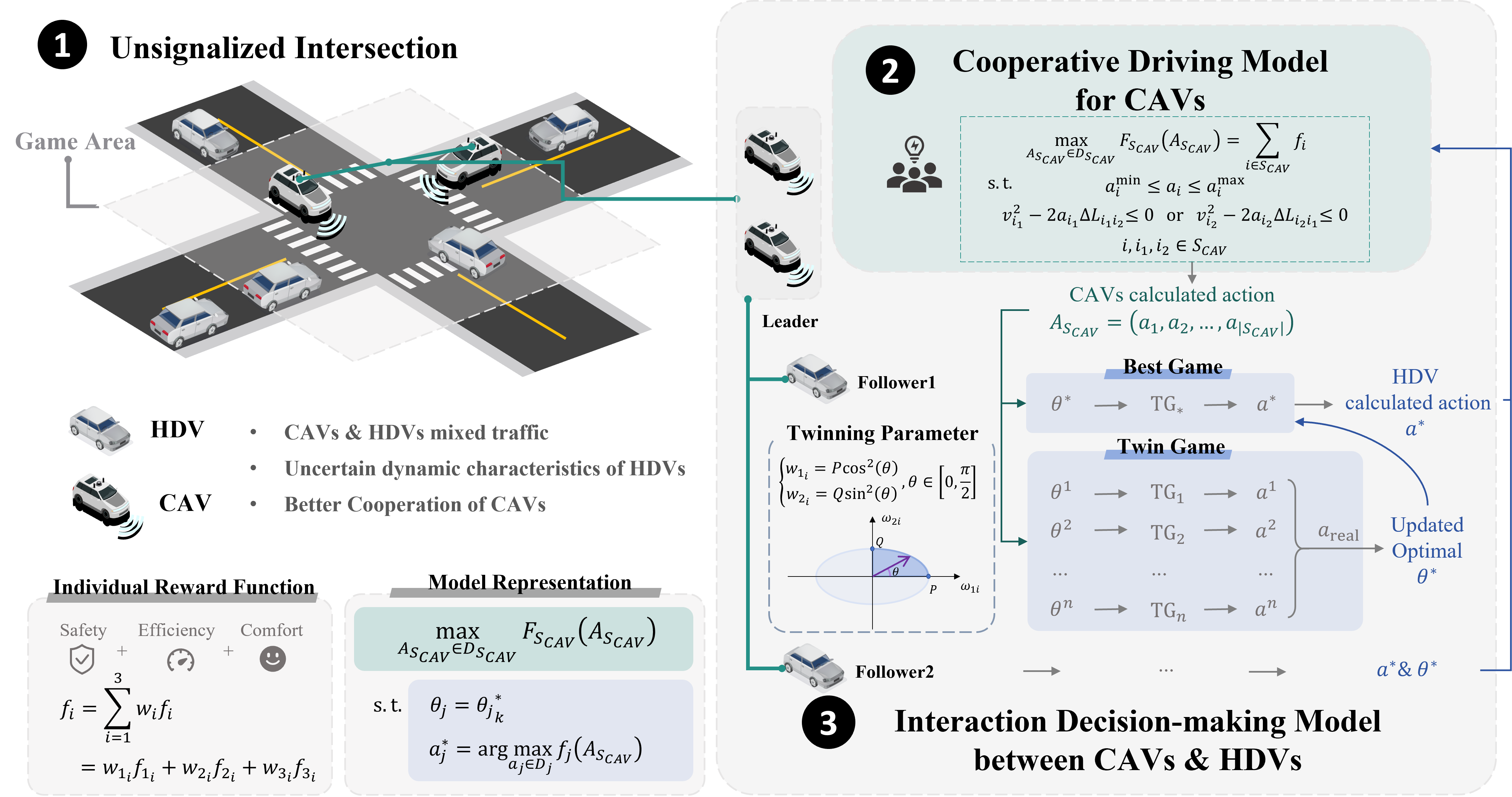
In terms of this complex conflict problem and realize safe and efficient cooperation in mixed traffic, we design a multi-vehicle cooperative decision-making method coupled with the interaction between CAVs and HDVs and the cooperation of CAVs based on game theory. For individual vehicles, we adopt a unified design of the utility function, taking into account the needs of safety, efficiency, and comfort. The total reward for an individual is represented as the weighted sum of three indices. The entire model is expressed as a bi-level optimization problem, structured such that the objective is to maximize the overall reward of cooperative CAVs, with constraints on maximizing the reward of each HDV.
Specifically, we proposed a cooperative decision-making model of the whole CAVs based on the cooperative game to achieve the decision action of CAVs. It is modeled as a single level constrained optimization problem to maximize the total rewards of CAVs. Security Hard constraints are designed to meet the most basic security guarantees between CAVs. The CAVs forming cooperative relationships need to satisfy a series of principles including individual rationality and group rationality.
Secondly, we establish an interaction model between CAV and HDV based on the Stackelberg game. In this part, we treat all CAV as a whole and build the model structure of leader-multi-followers. The model is modeled as a bi-level programming problem due to the general solving method of Stackelberg model. We designed parameters to characterize the differences in driving behavior between different human drivers and at different times in the interaction process. Moreover, we design the update rule of weight of HDV’s reward function based on the twin game, and realize the parameter adjustment to adapt to the dynamic interaction uncertainty of HDV. Security Hard constraints are designed to meet the most basic security guarantees between CAV and HDV.
Finally, to demonstrate the feasibility and effectiveness of the cooperative driving framework, cases are designed for experimental verification from multiple perspectives. We conduct the comparison of the simulation results with different methods which contains rule-based, reservation-based and reinforcement learning-based methods. Additionally, we did some validation experiments to verify the feasibility of method application including CAVs cooperative algorithm verification of domain controller in the loop and collaborative algorithm verification in mixed traffic of human driving in the loop.
Simulation
Comparative Evaluation of Different Methods
Three kinds of methods that are reservation-based and reinforcement learning-based methods are designed based on the above environment, and the simulation results are compared with the proposed method. For the method in this paper, two cases are designed, respectively.
FIFO
Choose First in First Out (FIFO) method as one of the reservation-based method. Specifically, only one vehicle at the same time is allowed to enter the designated area within a certain range of the intersection (in case design, the range within 10m before the stop line and the intersection conflict area).
PIDM
Virtual platoon projection method converts the two-dimensional spatial position of a vehicle into a one-dimensional position by referring to the position of the conflict point between the two vehicles. The platoon formed after projection can calculate the longitude decision action according to the car-following model like IDM, called Virtual-IDM.
singlePPO
As for the reinforcement learning method, Proximal Policy Optimization (PPO) algorithm has high computational efficiency, can deal with continuous action space and discrete action space problems, simple implementation, wide application range. The baseline PPO algorithm provided in Stable-Baselines3 was selected as the comparison method. And PPO interact and train the model in the environment provided by highway-env.
G-Nontwin & G-Twin
For the method in this paper, two cases are designed, respectively, the parameters related to the weight of HDVs reward function are determined and updated by the twin game and the parameters are fixed which are always the initial ones.
Scalability Analysis with Varying Number of Vehicles
Experiment
Scenario-(1) Unprotected left turn of 2 CAVs
The first experiment involved a scenario of an unprotected left turn with two CAVs to verify the possibility of CAV cooperative algorithm deployment and application under purely CAVs. Approaching from opposite directions on a stretch of road, one vehicle proceeded straight while the other executed a left turn.
Scenario-(2) Mixed traffic of 3CAV & 1HDV
In order to verify the effectiveness of the collaborative algorithm and the twin game in the mixed traffic scenario, the second experiment was conducted in the scenario of three CAVs and one HDV. Three subjects with different driving styles were selected to complete the driving task of HDV and interact with three CAVs in the designed scenario.
Driver1
Driver2
Driver3
Appendix
Background Vehicle Model: IDM and MOBIL Models
Intelligent Driver Model (IDM)
The acceleration of the HDV is given by the IDM as shown below:
\[a_f(s,v,\Delta v) = a_{\max}\left[1-\left(\frac{v}{v_{\mathrm{d}}}\right)^\delta-\left(\frac{s^*(v,\Delta v)}{s}\right)^2\right]\] \[s^*(v,\Delta v) = s_0 + v T_g + \frac{v \Delta v}{2\sqrt{a_{\max}a_{dd}}}\]Where:
- $a_f(s,v,\Delta v)$: acceleration derived from IDM
- $v_{\mathrm{d}}$: desired velocity
- $\delta$: acceleration exponent
- $\Delta v$: velocity difference between the front vehicle and the subject vehicle
- $s$: distance between the front vehicle and the subject vehicle
- $s^*(v,\Delta v)$: expected distance
- $s_0$: minimum stopping distance
- $T_g$: desired time gap
- $a_{\max}$: maximum acceleration
- $a_{dd}$: desired deceleration
Minimizing Overall Braking Induced by Lane changes (MOBIL Model)
Furthermore, MOBIL achieves safe and efficient traffic flow by minimizing the overall braking caused by lane changes, which mainly includes two parts: lane change incentive and safety inspection.
Lane Change Incentive
The lane change incentive evaluates the change in the acceleration of the ego-vehicle and surrounding vehicles to determine whether a lane change is warranted:
\[a_{c,old}-a_{c,new} + p(a_{n,old}-a_{n,new} + a_{o,old}-a_{o,new}) \geq \Delta a_{\text{th}}\]Where:
- $a_{c,old}$ and $a_{c,new}$: acceleration of vehicles before and after the lane change
- $c$, $n$, and $o$: ego vehicle, new follower, and old follower
- $p$: politeness coefficient, indicating the attention given to surrounding vehicles
- $\Delta a_{\text{th}}$: acceleration gain required to trigger a lane change
Safety Inspection
In order to ensure the safety of a lane change, the MOBIL model carries out a safety inspection to ensure that the lane change will not cause a sudden brake on the rear vehicle of the target lane:
\[a_n \geq -b_{\text{safe}}\]Where $b_{\text{safe}}$ is the maximum braking imposed on a vehicle during a cut-in.
Contact
If you have any questions, feel free to contact us (2310796@tongji.edu.cn).